Case Study — SaaS MVP · User Research · Product Strategy
SaaS MVP Research
Research isn't decoration. Hypothesis-driven validation that changed what a startup believed about their own users — before they built the wrong product.
01 — The Situation
A team ready to build, and a product no one had tested
Tech Leap had spent four months developing the concept for Wingman AI — an AI-powered coaching tool for B2B sales reps. The product vision was clear: real-time suggestions surfaced during live sales calls, helping reps handle objections, stay on script, and close faster.
The founding team was experienced. They had spoken to a handful of sales managers who were enthusiastic. Engineering was scoped and ready to sprint. And then someone asked the question that should have come first: have we actually talked to the people who would use this every day?
The answer was no. They had talked to buyers — the managers who would approve the purchase — but not to the sales reps who would be staring at a screen while on a call with a prospect. I was brought in to run four weeks of discovery research before a single line of product code was written.
02 — My Role
Sole researcher. Direct line to the founding team
I led all research activities end to end: study design, participant recruitment, moderated interviews, synthesis, and the final strategic brief that redirected the team's product thinking.
I reported directly to the co-founders and presented findings in three working sessions over the four-week engagement. This was not research-for-the-sake-of-a-report — every finding connected explicitly to a decision the team was about to make. The framing I used throughout: what do we need to believe to be true for this product to work, and is it true?
03 — The Hypothesis
Six assumptions. Two of them right
Before any interviews, I sat with the founding team to surface every assumption baked into their product concept. We listed them explicitly and scored each one on two axes: how central is it to the product concept, and how confident are we that it's true?
The riskiest assumptions — central to the product but unvalidated — became the research questions. We entered the field with six specific hypotheses to test.
| Hypothesis | Confidence going in | Result |
|---|---|---|
| Sales reps want real-time suggestions during live calls | High | Invalidated |
| Pre-call preparation is a key pain point for reps | Low | Confirmed |
| Junior reps are the primary user segment | High | Invalidated |
| Reps want visibility into their own performance data | High | Partially true |
| Sales managers will champion adoption | High | Confirmed |
| CRM integration is a prerequisite for purchase | Medium | Partially true |
Four of six central hypotheses were wrong or more complicated than assumed. The product that would have been built based on those assumptions would have served the wrong moment, for the wrong person, with the wrong feature prioritisation.
04 — Method
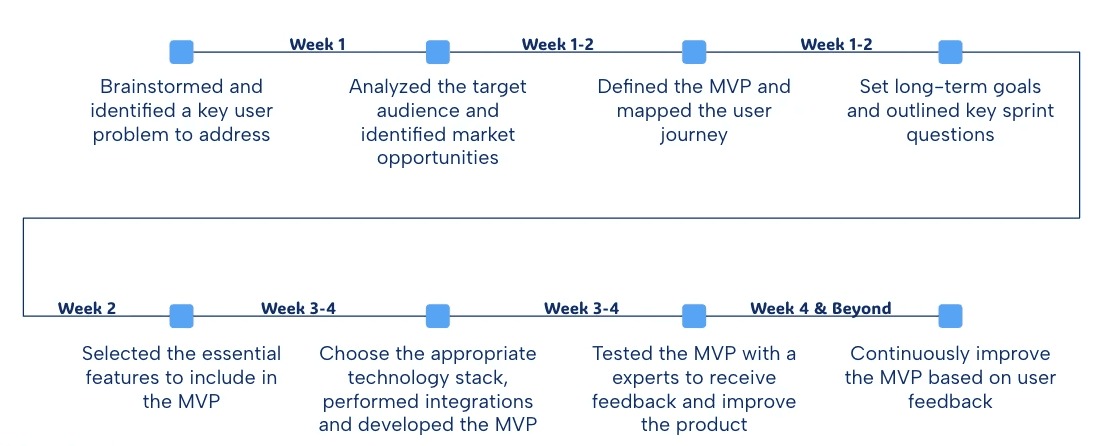
Structured to produce decisions, not insights
The research was designed from the output backwards: what decisions need to be made by the team at the end of week four? I mapped these decisions, then designed a mixed-methods study to answer them.
05 — What We Found
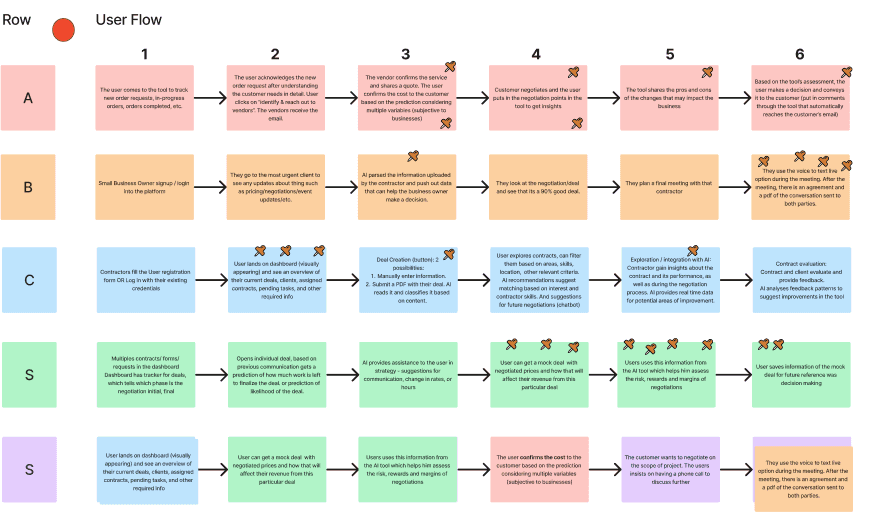
The product team didn't know their user
"I don't want suggestions popping up while I'm listening to a prospect. That would throw me completely. What I need is to walk into the call already knowing what to expect."
Real-time in-call suggestions — the centrepiece of the product — was rejected by 14 of 18 reps. Not because the technology seemed far-fetched, but because the moment was wrong. A call is not a moment for AI assistance; it's a performance. The cognitive load of processing a suggestion while listening to a prospect and formulating a response was described, unprompted, by multiple participants as "exactly the kind of distraction that kills deals."
The real pain was upstream. Pre-call preparation — researching the prospect, reviewing previous interactions, predicting likely objections — was something every rep did, and almost everyone found frustrating. It was time-consuming, inconsistent, and scattered across four or five tools.
The secondary finding was about who the user actually was. The founding team had designed for junior reps who needed coaching. But junior reps were the least motivated to use a new tool — they followed process and hoped to get out of the role quickly. The power users were mid-level reps who had already developed an instinct for selling and wanted to sharpen it. They were more self-directed, more tool-aware, and more likely to champion adoption bottom-up.
The privacy finding was the one that most surprised the founding team. Performance data was assumed to be a feature. But for most reps, sharing call quality scores with management was a threat. If the product surfaced individual performance data to managers by default, adoption would collapse. The product needed to be clearly rep-controlled before it could earn trust.
06 — Key Decisions
Three pivots the research made undeniable
07 — Outcome
Three months of engineering time redirected before it was spent
The founding team left the engagement with a repositioned MVP brief, two revised personas, a new understanding of their primary user's privacy concerns, and a roadmap in which the most technically complex feature had moved from phase one to phase three.
The research also produced an unexpected commercial output: by framing Wingman AI as "built for reps, not for managers," the team identified a positioning angle that differentiated them from every competitor in the space — all of whom sold top-down to management. This became their go-to-market angle for early trials.

08 — Reflection
The most valuable thing research can do is stop the wrong work
This project didn't produce a design. It produced a change in what the team was going to design. That is harder to package as a portfolio piece than a screen or a prototype — but it is often where UX creates the most leverage.
The challenge in research-only engagements is maintaining credibility when you are the person telling a founding team that their core assumption is wrong. The table of hypotheses — entered before the field, scored honestly afterwards — was what made the findings feel rigorous rather than opinionated. The team couldn't argue with a framework they had helped create.
If I were running this study again, I would add a concept test earlier — a lo-fi prototype of both the original and the repositioned concept, shown to the same 18 participants — to produce a direct comparison the team could see rather than read. The research was strong. The evidence would have been stronger.